(every? pos? [1 0 100])
;;=> false
user> (every? pos? [1 10 100])
;;=> true
February 9, 2022
Weekly Bits 03/2022 - Domain Modeling, Finite State Machines, Time Series, Api Security, and Impact Mapping
Table of Contents
Clojure
PF.tv Domain Modeling series
As in the week before, I’ve been reading through some of the Domain Modeling posts on the PurelyFunctional.tv blog, notably:
452: Domain Invariants
domain model consists of information, operations, and invariants
some places to encode invariants: types, (property-based) tests, language features, data structures, runtime checks / assertions, documentation, proofs
453: Model as Toy
write the model down to spot potential problems - the earlier the better
you have a model anyway, it’s just often ad hoc and partially written
455: How and when to apply domain modeling
Erik got a question if he applied domain modeling to a real project.
And he talked about a document signing example:
They could do a basic contract signing flow: Create a contract, enter email addresses, and it sends it to everyone to sign.
But customers wanted more control:
They wanted to say what order people had to sign in.
And they wanted other things besides signing, like a review step
⇒ hard to fit these new ideas into the simple model
The direct path was just more HTTP endpoints and SQL update statements and a bunch of conditionals
But thinking hard brought an idea of state machine (see also Code Hale’s article below)
especially the non-determinism allowing parties to sign in different order
The (state machine) idea was hard to sell, especially to engineers!
but just the process of modeling it with a state machine made them find some quick wins (like separating SQL updates into more atomic actions) which eventually simplified their model/code
Clojure cheatsheet - collections functions: every?, not-every?, not-any?
every? (hopefully obvious)
not-every? (read "at least one that is not")
it’s a complement to
every?
(not-every? pos? [1 0 100]) ;;=> true (not-every? pos? [1 10 100]) ;;=> falsenot-any? (read "none")
Note: any? is a completely different predicate (it’s not really a collection function - it returns true for any argument, including nil)
(not-any? pos? [-1 0 -100]) ;;=> true user> (not-any? pos? [-1 0 100]) ;;=> false
Downloading zip file from an URL via clj-http in Clojure - e.g. Amplitude Export API
I needed to download product analytics data from Amplitude. Amplitude’s Export API generates a zip file that you can download and extract. Here’s a way to download such a file in Clojure:
(defn download-events! [output-file start end]
(let [{:strs [api-key secret-key]} @api-keys
response (http/get (format "https://amplitude.com/api/2/export?start=%s&end=%s" start end)
{:basic-auth [api-key secret-key]
:as :stream})]
(io/copy (:body response) (io/file output-file))))
(download-events! "all-events-in-january.zip" "20220101T00" "20220131T23")Here’s a link that may help too: https://stackoverflow.com/questions/32742744/how-to-download-a-file-and-unzip-it-from-memory-in-clojure
Apache Commons Compress
I used this piece of code based on commons-compress library in the past when dealing with compressed files:
(defn- tar-gz-seq
"A seq of TarArchiveEntry instances on a TarArchiveInputStream."
[tis]
(when-let [item (.getNextTarEntry tis)]
(cons item (lazy-seq (tar-gz-seq tis)))))
(defn- unpack-archive-files
"Given a .tar.gz unpack it and process every entry via `unpack-file-fn`."
[compressed-input-stream unpack-file-fn]
(let [tis (TarArchiveInputStream. (GZIPInputStream. compressed-input-stream))
tar-seq (tar-gz-seq tis)]
(doseq [entry tar-seq]
(unpack-file-fn tis entry))))Coda Hale, Dan McKinley and Finite State Machines (and more)
Through the Fourteen Months with Clojure blog post I discovered a few very interesting posts by Coda Hale and Dan McKinley (see also Data Driven Products).
On The Difficulty Of Conjuring Up A Dryad
Talks about three topics:
A Finite-State Machine
One of their earliest major design decision was to model the Skyliner deploy process as a Finite-State Machine (FSM), with transitions from one state to another associated with specific conditions and actions.
For example, a deploy in the rollout-wait state will check the newly-launched instances of the deploy.

If the instances are up and running, the deploy is advanced via rollout-ok to the evaluate-wait state.
If the instances have failed to launch, the deploy is advanced via rollout-failed to the rollback state.
If the instances are still launching, the deploy is kept in the rollout-wait state via rollout-in-progress.
A Reliable Coordinator (Amazon SQS) SQS has a very robust model for dealing with failures: when a consumer polls the server for a new message, it specifies a visibility timeout
Similarly, when sending a message to a queue, one can specify a delay
They use the delay and the visibility timeouts to create "ticks" for deploys.
When a deploy is started, they would send an SQS message with the deploy ID, environment, etc. using a delay of e.g. 10 seconds.
After 10 seconds, it becomes visible to a Skyliner background thread, which receives it using a visibility timeout of e.g. 10 seconds.
The thread looks up the deploy’s current state and takes any appropriate action to advance it.
If the deploy has finished, the thread deletes the message from the queue.
Otherwise, the message is left in the queue to reappear after another 10 seconds has passed.
Blue-Green Deploys
Instead of modifying servers in-place and hoping nothing goes wrong, they leverage EC2’s elasticity and launch an entirely new set of instances
roll back by terminating the new instances
You Can’t Have a Rollback Button
The fundamental problem with rolling back to an old version is that web applications are not self-contained, and therefore they do not have versions.
They have a current state - the application code and everything that it interacts with. Databases, caches, browsers, and concurrently-running copies of itself.
One example of the problem - corrupting a cache (simple rollback might not fix the cache)
Takeaway: favor feature flags (disable them if there’s a problem) and roll forward (reverting a smaller diff instead of trying to revert all the other changes that were also released with/since the problematic change)
Note: Skyliner.io has been shut down a long time ago so it’s not active anymore. But the articles were nevertheless very interesting.
AWS & Cloud
Audrey Lawrence on Time Series Databases & Amazon Timestream
A really good podcast about Amazon Timestream and how time series databases work in general
Quick Timestream notes
Time series is capturing historical measurements
Problems with storing time series data in traditional databases
scaling
visualizations
etc.
2-D tiles for partitioning and scaling
Age-out / Roll-up older data for efficiency
In some domains you want to keep the granular data indefinitely (liike finance)
Memory store vs Magnetic (disk) store
you can specify Data retention (possibly for every table) for both
flexible schema - you don’t have to specify it upfront
Timestream is a serverless database (another example is Amazon DynamoDB)
you don’t manage servers anymore ⇒ aggresive scaling, automatic patching
It’s mostly append only:
records cannot be deleted or updated
(My) open question: how can you remove sensitive data, such as when a customer demands deleting it (GDPR)?
For a deeper dive there’s an excellent talk AWS re:Invent 2020: Deep dive on Amazon Timestream. I include a couple of examples from the talk:
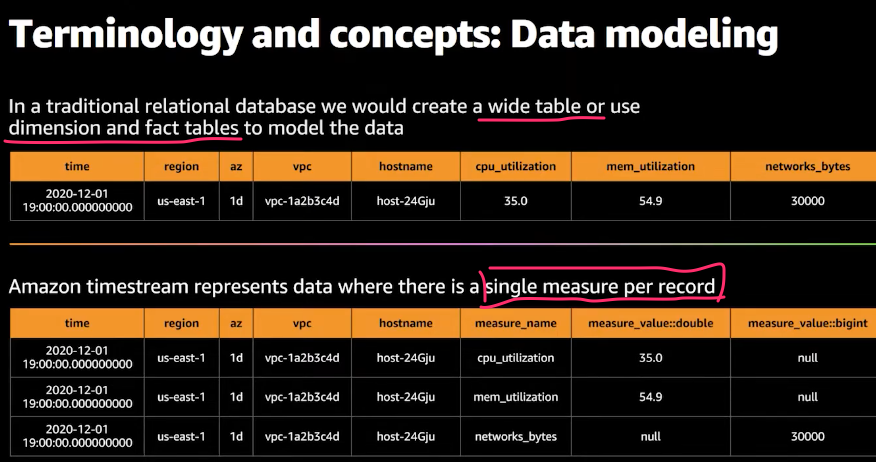
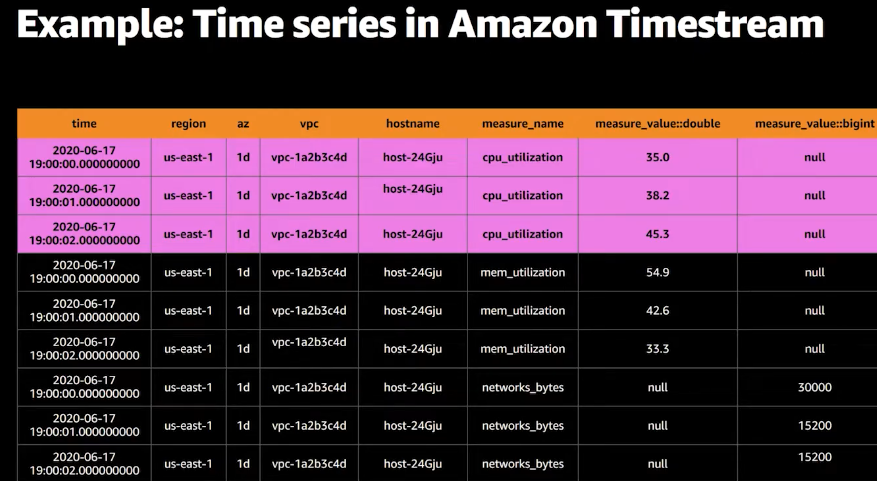
Books
Grokking Simplicity (started)
Book intro
Two main ideas/skills: * distinguishing actions, calculations, data * using first-class abstractions such as higher-order functions (powerful technique for reuse to pass functions to other functions)
Chapter 3: coupon email process & process diagram (very useful!)
I created the repo and added some examples
Data should ideally mirror the structure of the domain
Records of the DB at given point in time are just data
Separate data generation from its usage
Split large calculations into smaller - e.g. "plan list of emails" into:
select good coupons
select best coupons
decide coupon rank
generate email
An action "ties it all together"
When you need to optimize the process start in the high-level action - e.g. processing data in pages instead of all at once - calculations often don’t need to change at all!
Note: I’m a bit annoyed by the book using old-style JavaScript array iteration instead of more concise array methods. It makes the code examples unnecessarily verbose.
Api Security in Action - HMAC & Timing attacks
On pages 172 - 176, there’s a great explanation of HMAC and how it can be used to mitigate database timing attacks and fake token injection.
The process is roughly:
a simple hash is stored in the database and HMAC tag is appended to the token
the token-hash.tag is given to the client and tag is computed for every request
/* token generation */ tag = hmac(tokenId) // return this token to the user; store tokenId in the DB userToken = tokenId + "." + Base64.encode(tag) /* request veritification */ providedTag = Base64.decode(token.substringAfter(".")) computedTag = hmac(realTokenId) // using MessageDigest prevents timing attacks if (!MessageDigest.isEqual(providedTag, computedTag) { // invalid tag -> return/throw without querying the DB } ...
And it helps because:
invalid requests which produce an invalid tag are rejected immediately without DB query thus preventing timing attacks
make sure to use MessageDigest.isEqual to compare the expected and the computed HMAC tag
token (SQL) injection is prevented because an attacker cannot produce a valid hash even if they have access to the database (they don’t have the secret key)
Practical Monitoring - Basic statistics
Chapter 4 in the book is short but practical (as the whole book even though it focuses on principles and not particular tools).
It’s a quick tour of the most basic statistics like mean, median, and percentiles.
It says that standard deviation is rarely useful because we mostly deal with not-normal distributions (skew)
It also talks about an important statistical concept, seasonability - repeating patterns like a weekly cpu usage.
They advise us to look for skew, outliers, and bounds when thinking about your data
50 Quick Ideas to improve your user stories
Impact mapping
Powerful technique, hierarchical backlogs
read the Book Sample: https://www.impactmapping.org/assets/impact_mapping_20121001_sample.pdf
Impact mapping has several unique advantages over similar methods:
[based on interaction design] facilitates collaboration and interaction between both technical experts and business users
It visualises assumptions - Alternative models mostly do not communicate assumptions clearly.
supports effective meetings and big-picture thinking
It’s fast - a couple of days might save you months; it fits well with iterative delivery
Actors - focus who will benefit from it and who will be worse off when it is delivered
do not focus on software features / capabilities
define actors in this order: specific individual, user persona, role or job title, group or department
Goals - very few people working on delivery know the actual expected business objectives
sometimes drafted in a vision document, but more frequently exist only at the back of senior stakeholders’ minds.
By having the answer to ‘WHY?’ in the centre, impact maps ensure that everyone knows why they are doing something.
Impacts - understand what jobs customers want to get done instead of their ideas about a product or service.
consider negative impacts too - e.g. increasing number of customers will likely increase load on the support team
Deliverables - start only with high-level deliverables
You can break down high-level features into lower-level scope items, such as user stories, spine stories, basic or extension use cases later.
MISC
PurePerformance podcast
Microsoft Excel highlighting duplicate values & hiding columns
Highlighting duplicate values: https://answers.microsoft.com/en-us/msoffice/forum/all/2011-excel-for-mac-how-to-highlight-duplicate/7afdb7e3-a9f7-4dfc-a410-a49907e4448b?auth=1
Go to Format - Conditional formatting