February 20, 2022
Weekly Bits 04/2022 - Domain Modeling, Cryogen, AWS Secrets Manager, Api Security, VisiData, and more
Table of Contents
Some of the interesting things I did, learned, or found in the past week.
PF.tv Domain Modeling series
I’ve been reading through some more Domain Modeling posts on the PurelyFunctional.tv blog, notably:
457: Take a stance
People are often worried they create a wrong model because they cannot predict the future.
Let’s analyse the fear:
Don’t worry - your model is already wrong
if you don’t even write it down then you will never learn how bad it is
No model is perfect - just finding a better model (fit) will be great ⇒ fewer corner cases, less code, more development speed
You can change the model later - it’s just code and data (although it’s more expensive as you have more data and handle more use cases)
Build flexilibility into your model - if you can predict specific areas where you need it (follow your fear to explore such areas)
For instance, modeling pizza toppings (that can change even daily) by allowing ingredients to change quickly and easily (one option is to store them in a DB table instead of hard-coding)
Push decisions into a higher layer (make the lower layer more generic than immediately needed)
e.g. using inches to measure a diameter of pizzas - at the higher level, you can translate inches into 'small', 'medium', 'large'
good domain models are more general than we need at the moment ⇒ we can reuse them in novel situations
Have the conversation - with business stakeholders and customers
domain model constraints are helpful (e.g. having only rounded pizzas, not squares)
if they want arbitrary shapes, we need to consider that but otherwise we shouldn’t allow for arbitrary things in our model
458: Three doorways of domain modeling
The three levels for Domain Modeling - more fundamental first - are:
data modeling - some data models fit the world better
mirror the structure of the domain - evaluate language features (such as interfaces and enums) for their modelling potential
operations first - realize that you can design the operations over the data independently of the representation of the data
design operations ahead of the data model and analyze how those operations constrain the data modling choices
algebraic composition - some set of operations are more expressive than others
designing operations to compose - design algebraic properties of your operatios to create expressive domain languages
460: Interface polymorphism
An Interface encodes alternatives
Suggested approach: find the alternatives - identify them and see how fast they change → e.g. coffee sizes:
if the coffee sizes don’t often vary, use an enum
if you add/remove sizes weekly, perhaps an interface is best
if it changes daily, you may need something better - perhaps store the sizes in the database ("data class" approach)
We need to talk more about correctly choosing our abstractions to encode a domain model and less about rules of thumb for making code more maintainable
Clojure
Fixing Cryogen’s auto-refresh
I was missing the auto-refresh feature when working on the blog posts and finally figured it out.
There’s a server option called
:fastthat I tried, but it doesn’t seem to work: https://github.com/cryogen-project/cryogen/blob/master/src/leiningen/new/cryogen/src/cryogen/server.clj#L84there’s even alias :fast in deps.edn (although it’s missing :exec-fn)
⇒ I fixed the alias here: Add missing :exec-fn to the :fast alias in deps.edn. #250
It still didn’t work for me because the Nucleus template uses another function window.onload which overwrites the javascript used by ring’s refresh mechanism
I also created an issue about this: Auto-refresh feature doesn’t work with Nucleus template. #251
Can "NUMA" cause mysterious performance degradations?
You’ll find an interesting discussion in a couple of blog posts and related links:
Core.async - channels as queues?
hiredman in #core-async (Clojurians slack) channels as collections is also pretty "meh"
channels are synchronization points between processes, that have queue like behaviors
Ben Sless: Channels are queue like, but I can reduce a java Queue. It might be nonsensical, but I don’t see a reason why reducing over a channel can’t return a channel which will contain a result sometime in the future like it does in core.async.
hiredman channels are queues, but what they queue isn’t values, they queue threads of execution
channels are points where threads of execution can exchange values, and if no thread is currently at that point, a thread of execution can be queued waiting for another to arrive to exchange a value with
AWS & Cloud
AWS Lambda deployment with Terraform
I had a lot of fun deploying a new lambda function with Terraform this week. There are quite a few steps you need to accomplish even for such a simple thing and I think it’s useful to summarize them. I’ll try to do that in a future blog post.
AWS Secrets Manager and the principle of least-privilege
AWS Secrets Manager is a great place to store secrets that are needed by somebody else (machines or people) if you are running your infrastructure on AWS.
You can give subjects (users, groups, or roles) accesss only to specific secrets following the principle of least privilege.
*I wrote a separate blog post about this topic: AWS Secrets Manager and the principle of least-privilege
AWS Load Balancers - increasing the idle connection timeout
[On DevOps Engineers slack] Is there any downside to increasing the idle connection timeout on an ALB (assuming it’s still less than the application timeout)?
Cost would be the big one. Scaling not so much
LCUs [Load Balancer Capacity Units] are based on new and active connections (plus rule evals and bytes processed) so keeping the connection open would increase LCUs/cost. It is wise to keep it > than the app timeout, I’ve ran into issues where the app timeout was set to X and the ALB timeout was X-Y and had connections drop in the middle of large uploads, etc.
Books
Explore it!
This book looks really good and I’m looking forward to reading it.
From the publisher’s blurb:
Rather than designing all tests in advance, explorers design and execute small, rapid experiments, using what they learned from the last little experiment to inform the next. Learn essential skills of a master explorer, including how to analyze software to discover key points of vulnerability, how to design experiments on the fly, how to hone your observation skills, and how to focus your efforts.
Grokking Simplicity
Quick notes from chapter 4: Extracting calculations from actions:
Actions spread
Implicit vs explicit inputs & outputs
inputs - information from the outside that the function uses in a computation
outputs - information or actions that leave the function
implicit inputs: e.g. modifying global variable; explicit inputs: function’s arguments
implicit outputs: e.g. updating a DOM element or printing to the conslle; explicit outputs: function’s return value
Implicit inputs or outputs make a function an action!
Api Security in Action
Session fixation, Cookies, Sub-domain hijacking
On pages 119-125 they cover various interesting topics:
mitigating session fixation attacks by always creating a new session on login
Useful cookies attributes:
Secure- can only be sent over HTTPSHttpOnly- using this it’s harder to steal cookies via XSS attacksSameSite- only sent on reuests that originate from the same origin as the cookieDomain- preffer not setting it ⇒ the cookie will become host-onlyPath- set it to "/" if you want the cookie to be sent for all API requets because otherwise the default is the parent of the request that returned the Set-Cookie headerlimited security benefits - easy to hack by creating a hidden iframe with correct path
Max-Age- makes the cookie persistent (non-persistent cookie is removed when the browser closes)avoid setting it for session cookies BUT still enforce maximum session time on the server - one reason for this is that browsers support session restoration
check also standard cookie prefixes like
__Secure-and__Host-
Sub-domain hijacking - due to abandoned DNS records → often problem on shared hostings like GitHub Pages
CSRF
The next section (p. 125-133) talks about CSRF :
APIs that serve browser clients may still be vulnerable to CSRF and need to build in protection mechanisms
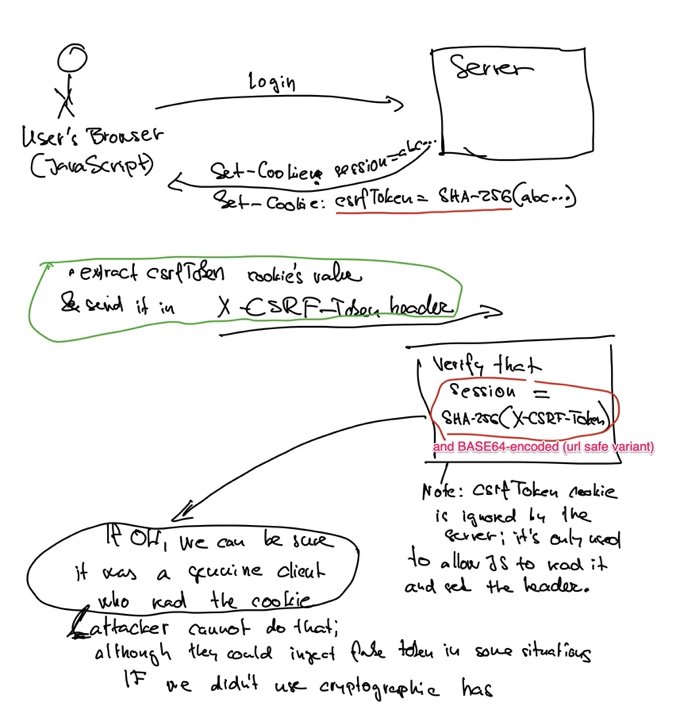
One of the most effective way are double submit cookies - the variant where the second token is cryptographically bound to the session cookie
This picture shows two tokens/cookies - session cookie, which is
HttpOnly, and the secondcsrfTokencookie which is cryptographically bound to the session cookie by using theSHA-256hash function:
Base64: url-safe variant is in common use for web apis because it can be safely used in URLs (see also Base 64 encoding, padding, and URLs)
The meat of the code checking the tokens:
// the provided token is expected to be Base64-encoded version of SHA256 of session token var tokenId = request.headers("X-CSRF-Token"); var providedToken = Base64Url.decode(tokenId); var computedToken = sha256(session.id()); if (!MessageDigest.isEqual(providedToken, computedToken)) { // somebody is trying to forge the token? return Optional.empty(); } // here's the code to compute sha256 MessageDigest.getInstance("sha256").digest(tokenId.getBytes(StandardCharsets.UTF_8));
Practical Monitoring - chapter 5 about Business Metrics
This chapter focuses on business KPIs and is extremely useful.
Things that stakeholders care about (questions they ask):
Can customers use the service and are they happy?
Are we making money?
Are we growing?
Common business metrics (p. 58): MRR, Revenue per customer, NPS, LTV, CAC, Customer churn, Active users, etc.
2 real-world examples: Yelp and Reddit
Yelp: searches performed, reviews placed, user signups, active users, active businesess, ads purchases
Reddit: users currently on site, user logins, comments posted, threads submitted, votes, private messages sent, ads purchased
Connecting Business KPIs to Technical metrics:
splitting things like User logins into more specific metrics like login failures and login latency
Writing
Apart from this weekly summary I published a couple short posts:
MISC
Base64 encoding
A colleague added spec for base64 encoded values in our codebase and that made me check what is actually a valid set of characters in a Base64-encoded string.
I wrote a separate post about this topic: Base 64 encoding, padding, and URLs.
Cognicast with Camille Fournier
"Leadership" is not the same as "People managment"
we shouldn’t force technical leaders into people management
Technical skills are critical for engineering managers
so they gain credibility among engineers
they need understanding, appreciation and taste for their engineers' work
Strategic thinking and building culture & engagement is hard when working fully remote
VisiData - a great tool for exploring CSV (and many other formats) on the command line
VisiData is an extremely interesting and useful command-line tool for exploring tabular, CSV, JSON, and other formats.
Make sure to check VisiData Lightning Demo at PyCascades 2018.
My favorite stuff:
Shift + I→ descriptive statistics for the datasetShift + F→ frequency table (histogram)filtering:
\to select relevent rows, then"to open the current selection as a new sheet